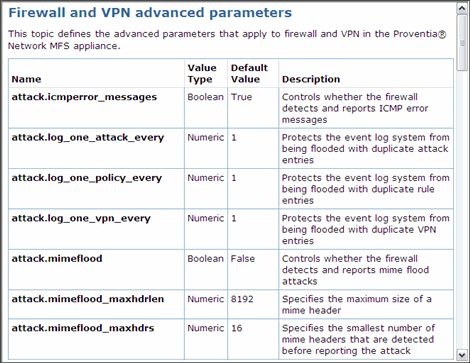
The Structure
A table is a two-dimensional array in which data appears in cells, taking its context from the intersection of a column and a row. The spatial orientation and placement of the data encodes the information. Thus, you should be aware that tables can present potential accessibility problems. While adaptive technologies can process simple tables that have been properly coded, complex tables can be a barrier to sight-impaired users if they are not implemented correctly—even if they are well designed like the examples I’ve shown in this column. Seek the advice of an accessibility expert when putting complex tables into an application or user assistance document.
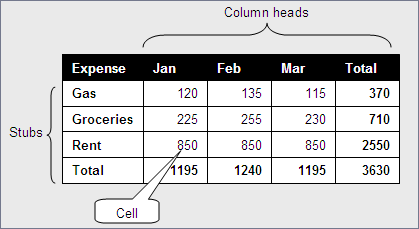
Figure 1 illustrates the essential components of a table. Each cell’s data takes its meaning from its respective row stub and column head. For example, the captioned Cell indicates that the rent for January was $850. In instances where every cell has the same unit of measure—dollars for example in Figure 1—each row and each column could have its own total. In the case of Figure 1, this makes it easy to see both the total amount spent on rent and total expenses for January.
The first decision an information developer must make is which items should go into the columns and which should go into the rows. A general guideline: Let users compare like items by scanning horizontally across a row and aggregate unlike items by scanning vertically down a column.
Note—Reference tables, which I’ll discuss later in this column, are an exception to this guideline.
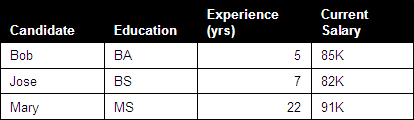
Figure 2 shows a table that compares the attributes of three different candidates for a job opportunity. It follows users’ natural instinct to compare specific attributes for candidates by scanning horizontally. It also lets users get a summary of each candidate’s attributes by scanning vertically down a column.
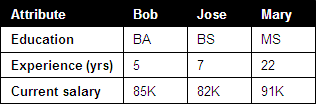
Figure 3 does not follow this natural layout. Most readers would find the configuration of the table in Figure 2 easier to process than that of the table in Figure 3.
To accommodate physical display limitations, you might, in some cases, have to make exceptions to this guideline. For example, if there were 20 job candidates to compare and contrast, but only three criteria, you should probably place the job candidates in the stubs and the criteria in the column heads. When displaying data online, you have to be especially sensitive to any layout that would force horizontal scrolling.
Managing Complexity
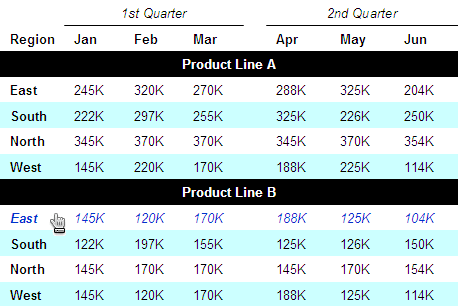
Tabular data can get complex, and a table can contain several stories, with subplots occurring at once. The example table in Figure 4 presents sales information by month, by region, by quarter, and by product line, resulting in a so-called zebra table that has both spanner heads and section heads.
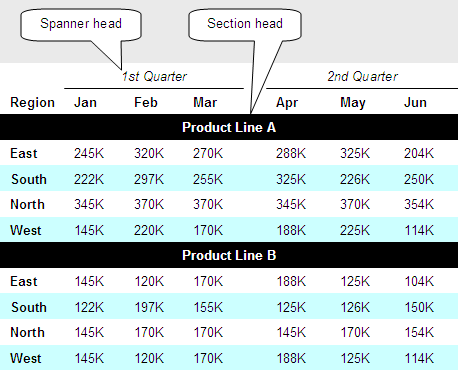
Let’s take a detailed look at how the table shown in Figure 4 handles such complexity by using the following:
- minimalist lines—To reduce visual complexity, I’ve removed all cell borders, including the table’s exterior border. Alignment and white space adequately communicate the columnar and row associations. Notice, though, that the spanner heads use lines to clarify what columns are under them.
- zebra shading—To help users’ eyes scan data across a row and reduce tracking errors—which occur when their eyes wander to an adjacent row—I’ve shaded alternate rows. Visual designers sometimes call this kind of table a zebra table. You can apply shading to columns instead of rows, but shading rows is more common.
- spanner head—A spanner head groups columns together. In Figure 4, spanner heads group and identify information by quarter, and white space separates the quarters.
- section head—Section heads divide a table into multiple tables, so to speak. However, you should use them only if the column headings do not change. It would be confusing, for example, if the months for Product Line B were different from the months for Product Line A.