Privacy Concerns
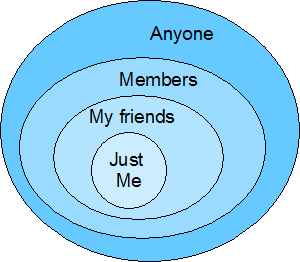
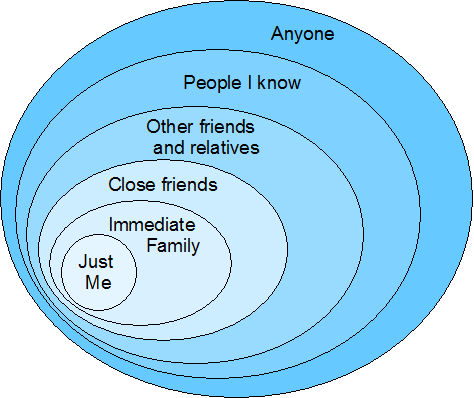
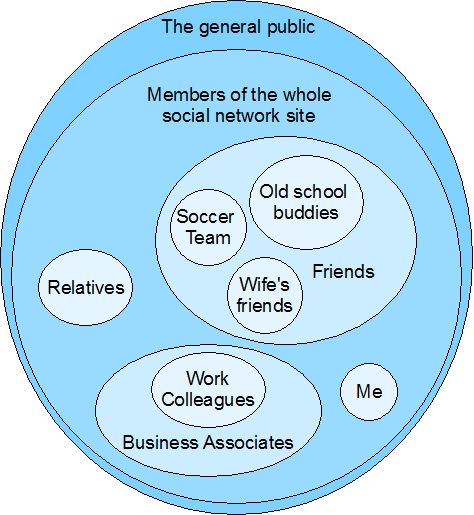
One of the major concerns about social networking services is users’ control over the privacy of their information—or more accurately, control over who gets to view what they publish. Such services should offer privacy protection that’s more substantial than a simple differentiation between stuff users’ friends can see and stuff that is open to the public. But providing more fine-grained control might impose a complex user interface that the majority of users couldn’t easily follow.
What we really need is a unifying metaphor—and its corresponding user interface—that captures various levels of interpersonal trust in a way that is both comprehensive and simple.
Historical Background
In the beginning, the World Wide Web provided a mechanism for a small number of information providers to publish information to a large audience. During the early 1990s, users could navigate and search this growing information space, but were fundamentally consumers who had no ability to contribute. [1] In this one-way medium, privacy issues were limited to cases where an organization deliberately published someone’s personal information on its Web site, and people dealt with such breaches of trust via personal communications and legal processes outside the medium.
During the late 1990s, the Web changed from an information space to an application space. In addition to finding information, users could interact with the published content—particularly by making product purchases online. This extended the Web into a two-way medium, but a relatively small number of participants controlled the scope of interaction—namely, the companies who hosted Web sites. It remained the case that only information deliberately published into the public space became visible to other participants. Nevertheless, the privacy of personal information such as credit card details was often a concern. Technological solutions could deal with one aspect of this concern—the fear that some third party might intercept the information people provided over the Web—so this problem has gradually disappeared with the increasing use and understanding of HTTPS/SSL since its introduction in 1994. Beyond that concern, however, the key privacy issue was whether Web site hosts were trustworthy. Web users often provided personal information as part of their transactions, in the belief that an organization collecting the information would both secure it from other parties and use it only for purposes relating to those transactions.
More recently, the Web has morphed again, this time into a social space where privacy becomes a more fundamental concern. The emphasis of Web 2.0 on social networking, sharing, collaboration, folksonomies, communal blogs, the wisdom of crowds, and user-generated content makes today’s Web more significantly a two-way medium than the Web was previously. A vast array of new sites promote the self-publishing of text, audio, and images, juxtaposing the right of attribution with the desire to limit distribution.
Outdated copyright laws provide some protection from what people may do with your published works. However, at its core, the Web has always been a public space where people share content freely. The mechanisms that allow private interactions within that public space—such as authentication schemes, Virtual Private Networks (VPN), levels of trust, and uses of encryption in systems like The Onion Router (Tor)—are extensions rather than essential components of the Web. As people increasingly use the Web for social networking, the need for control over privacy becomes an essential part of using the Web, even though it is not essential to the Web’s technology.
The Expectation of Privacy
Governments do not universally recognize privacy as a right, whether in the real world or cyberspace. Although some countries have legislated privacy matters, there are still important disagreements over individual versus communal rights, including claims that the state’s right to know things about its citizens sometimes overrules its citizen’s rights to privacy.
Putting aside political and philosophical issues, however, a central premise of any practical discussion about privacy on the Web is the fact that information on the Web is, at least by default, public. People’s complaints about social networking sites indiscriminately distributing their personal data on the Web are unconvincing when they have already made an explicit choice to expose that data in a public space.
Legislative and commercial pressures have caused most Web properties to include a privacy statement that describes the host organizations’ responsibilities with regard to how they treat users’ data. But those responsibilities do not extend to the protection of users from any unintended consequences of self-publishing in a public space.
Nevertheless, many people who use social networking services do so with the intention of limiting access to their published material to a select audience. They publish information with a reasonable expectation that these services will respect their intentions. Therefore, it behooves the providers of social networking services to implement privacy mechanisms that are both simple to use and sufficiently fine-grained to enable users to have adequate control over access to the material they publish. So, an effective privacy mechanism needs to deal with the following dimensions of a permissions model and answer these questions:
- Objects—Which personal information Objects do users choose to expose to other people, or Actors?
- Actors—To whom do users choose to reveal those Objects?
- Actions—What do users let the permitted Actors do with the Objects to which they have access?
Together, these requirements constitute just one special case of a broader task that information technology (IT) has addressed in many forms in the past. Virtually every operating system and every database management system has implemented some mechanism for controlling who has what type of access to which resources. The more mature examples of such mechanisms are role based rather than based on individuals—that is, administrators associate permissions with roles such as Accountant or Data-Entry Operator and grant or deny individuals’ access according to their assigned roles.
What differentiates privacy on social networking services from previous implementations of access control is their requirement for simplicity of use. In other contexts, trained IT system administrators who can cope with complex systems control the configuration of access rules. Consequently, breadth of functionality and fine granularity dominate the design task rather than usability. When a privacy system structures information objects hierarchically—as in a filing system—the inheritance of permissions compounds the complexity. For example, the file-level security of Microsoft Windows provides a very high degree of control, but few people can use it with confidence. In my own experience, even competent system administrators fiddle around with permissions until they achieve the desired behavior. Nobody I know gets it right the first time.
When users might be anyone with an Internet connection and a Web browser, designers must elevate simplicity to their highest priority. Unfortunately, to date, this has meant the sacrifice of important functionality.
Privacy Controls on Social Networking Sites
Current practice in social networking privacy focuses primarily on Objects, with only elementary regulation of Actors and virtually no attention to Actions. As a result, there has been a growing number of well-publicized stories about the painful consequences of social networking sites’ distributing personal material beyond its owner’s intention.
There is not a lot of variation in the approaches the major social networking sites have taken. One reason for this results from the nature of the interactions such sites promote. For instance, on Twitter, once you have set your account to either Public or Protected, there is no further control—and there doesn't need to be. Your tweet stream is visible to either everyone or just your followers. That’s as complex as it needs to be.
At the opposite end of the spectrum, the basis of tools like Google Wave, instant messaging applications, and online meeting services such as Cisco Meeting Place, GoToMeeting, and WebEx is a conversation metaphor that naturally restricts each conversation to invited participants.
The sites where explicit control of privacy becomes important are those that let users publish multiple types of information Objects—such as photos, personal information including demographic details, address books, personal opinions, and other types of user-generated content. Most sites of that nature let users restrict access across every type of Object their service supports. However, they do not match that fine level of granularity when it comes to defining the Actors or the Actions on those Objects. In virtually all cases, they support only one Action: the ability to view the exposed Object.
Throughout the rest of this article, I’ll focus on the granularity of control over Actors. This, I believe, is the area requiring urgent attention, and I’ll make some suggestions for improvements in that area.
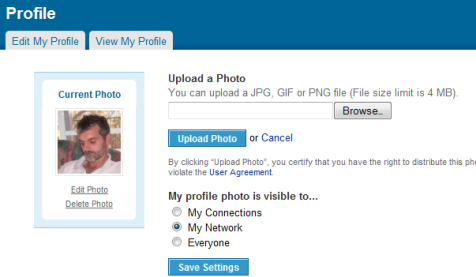
I’ll start with Facebook, because it seems to attract most of the flack, [2] while at the same time offering the most comprehensive set of controls on any site I have seen. On Facebook, dialog boxes similar to that shown in Figure 1 control access to most Objects. An Object’s owner can restrict access to the following Actors:
- Only Me—which provides complete privacy
- Some Friends—which permits an explicit list of people to access the Object
- Only Friends—which permits all friends to access the Object—of course, implying friends within the Facebook network
- Friends of Friends—which broadens access to all of a user’s friends, plus friends of their friends
- Everyone on Facebook—which makes the Object completely public
The Facebook options imply a hierarchy of privacy, including the ability to explicitly deny access to a list of selected people.
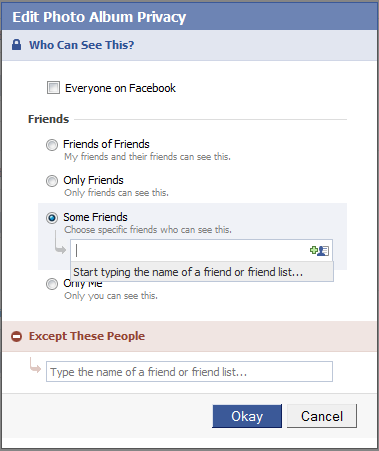
During the past year, Facebook seems to have expended a lot of effort modifying their privacy settings—both to make them easier to use and to extend the range of Objects to which they apply. But even after their most recent changes on December 10, 2009, it still looks like the site provides control over Actors at the wrong level of granularity. The categorization of Friends, Friends of Friends, and Everyone is too coarse; but the ability to specify a list of individuals is too fine.
I say it looks like this is the case, because there is actually a very powerful, though hidden feature whose level of granularity is in the Goldilocks zone—that is, just right. How many people know they can define arbitrary groups of friends via Facebook’s friend lists? My guess is that the difficulty of even finding that feature most likely results in its being seriously underused. Facebook has not even assigned a proper name to such lists. Users can place friends in as many named lists as they like. For example, a user could create one friend list called Business Associates and another called People I Don’t Trust, then, after selecting the Some Friends option shown in Figure 1, specify that anyone on the Business Associates list can view an Object, except those who are also on the People I Don’t Trust list.
Even if users are clever enough to know about friend lists, it is not immediately obvious that they can use them in this way. The tip text in Figure 1, Start typing the name of a friend or friend list…, erroneously led me to think I could type only a comma-separated list of individual friends. It was only when researching this article that I learned from Nick O’Neill![]() that this option lets users add not only individual friends, but also predefined friend lists.
that this option lets users add not only individual friends, but also predefined friend lists.